特性
主张无模式的数据 模式就是需要预先定义结构
可以运行在集群环境中
牺牲传统数据库的一致性
优势
开发效率更快 无需太多的关心数据结构和关系型数据库之间的映射 -> 无模式
适合大数据量场景 关系型数据库是为独立运行的计算机而设计 NoSQL为集群设计
模式
虽然NoSQL没有模式,但是数据在运用的过程中隐含了一种模式
在实现数据结构变更的时候,也必须修改其规则
关系型数据库的价值
- 持久化数据
- 并发安全 指的是事务
- 集成 多个应用程序可以共享数据(那时候还没有Http来交换数据)
- 标准化
关系型数据库的问题
元组中的值必须很简单 如果需要List,则必须再建立一个关系
ORM(object relation mapping)在一定程度上缓解了这个问题
NoSQL广泛使用的模型
- 键值
- 文档
- 列族
- 图
其中前三种是面向聚合
面向聚合
在领域驱动设计中,把一组相互关联的对象视为一个整体单元来操作,这个单元就叫聚合
比如学生选多门课
面向关系需要学生表记录学生,课表记录课,学生和课的映射表记录学生选了哪些课
面向聚合可能就直接一个JSON描述干净
面向关系的更像是(标记聚合 + 面向组合)的方式
因为集群的关系,面向聚合的数据库确实不支持跨越多个聚合的ACID事务
它每次只能在一个聚合结构上执行原子操作
聚合的有用之处在于它可以把经常访问的数据存放在一起
键值数据库和文档数据库
两类数据库都是面向聚合的
区别
键值数据库的聚合不透明
可以存储任意数据
访问聚合内容,必须通过Key来进行查找
文档数据库的聚合中可以看到其结构
限制存放的内容 定义了其允许的结构和数据类型
可以更加灵活的访问数据
用聚合中的字段查询,只获取聚合的一部分
按照聚合内容创建索引
列族存储
读多写少的场景
两级聚合结构
以一组列来存储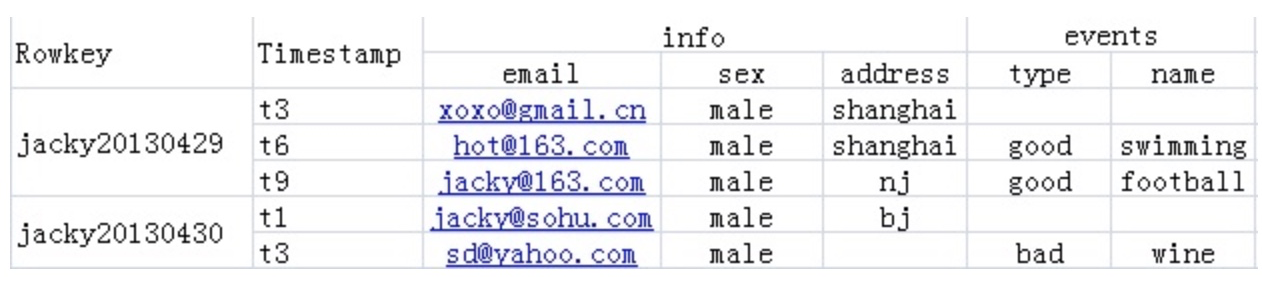
上图的info和events就是列族
由rowkey + (colomn family:colomn qualifier) + version来唯一的标志一个Cell
为什么叫列族呢
我个人理解的话
就是列是从关系型数据库去讲的,数据库的第一范式就规定了列必须是不可再分的
但是列族的话表示这是可再分的
一个列族包含了很多的列
列族中可以随意添加列
这样设计的理念是某个列族的数据经常要一起访问
总结
面向聚合数据库,都使用了聚合这个概念
而且聚合中都有一个可以查找其内容的索引键
聚合还是更新操作的最小数据单位
图数据库
如果两个聚合之间产生了关系,一个难点就是如何更新其数据
面向聚合的数据库,在操作多个聚合的时候显得相当笨拙
如果待处理的数据中包含了大量的关系
这意味了关系型数据库可能是更好地选择
虽然关系型数据库在这里这种情况的性能也很糟糕,但是至少能保证ACID
或者我们使用图数据库
图数据库特别擅长处理关系特别多的场景
图数据库和面向聚合的数据的明显的差异就是
它尤其的注重数据间的关系
再谈无模式
无模式数据库感知不到模式
所以它无法用模式来提升存储与获取数据的效率
也无法自行验证数据
带来的是使用的自由和灵活
所以NoSQL弃用模式,确实让人惊叹
隐含模式
不管数据库无模式到什么程度
总会存在隐含模式
指的是在编写数据操作代码时,对数据结构做的一系列假设
所以说隐含模式是在应用代码中
所以如果多个应用公用一个数据库
那么可能会出现问题
解决方法是在聚合中为不同的应用程序划分出不同的区域
物化视图
关系型数据库因为不存在聚合结构
所以可以用不同的方式访问数据
此外,还提供了视图的机制
数据分布
数据分布有两种途径
- 复制 将同一份数据拷贝到多个节点
- 分片 将不同的数据分放在不同的节点中
复制有两种形式
- 主从式
- 对等式
分片
因为NoSQL的面向聚合的特性
所以对于分片非常的适合
我们进行分片的时候,将聚合作为分布数据的单元
这样可以保证查询的时候只需要查询一个节点
分片工作可以
- 在客户端
- 自动分片
客户端的话,体验非常不好
- 若要调整分片,既要修改代码,又要迁移数据
分片对于读写性能的提升都是巨大的
主从复制
提升读性能,对写性能帮助不大
增强读取操作的故障恢复能力 (指的是不会自动选主的情况)
问题
保证数据不一致性
写读不一致,读读不一致
对等复制
没有主节点的概念
所有副本地位相同
都可以接收写入操作
还是一致性,顺序不一致
(加分布式锁?那性能咋办)
而且更难解决
结合分片与复制
就是Redis Cluster的方案
多主多从
一致性
关系型数据库中的强一致性
而在NoSQL中,则一般采用CAP与最终一致性
并发环境下维护数据一致性
- 悲观方式 避免发生冲突
- 乐观方式 先让冲突发生,然后检测冲突并对发生冲突的操作排序
悲观方式一般是加锁
乐观方式一般是“条件更新”
任意客户在执行更新操作之前
都要先测试数据和当前值和其上一次读入的值是否相同
测试和更新得是一个原子操作
顺序一致性
- 所有节点都要保证以相同次序执行操作
逻辑一致性
- 就是脏读的问题
逻辑一致性的解决依赖事务功能
NoSQL支持不支持事务还是得具体看的
如果不支持,那么就会出现问题
但是图数据库一般都是支持的
NoSQL的不一致窗口时间很短暂
复制不一致
- 主节点的更新向从节点复制的时候存在时间空隙
最终一致性
- 会话一致性 在用户会话内部保持“照原样读出所写内容的一致性”
方法:- 黏性会话:绑定到某个节点的会话 缺点:降低负载均衡器的效能
- 版本戳
CAP中的可用性是值
系统中某个无故障节点所接收的每一条请求
无论成功还是失败
都能得到响应
现在不是完全的CAP二选一
都是BASE理论
首先分布容忍性肯定要有
然后一致性和可用性要有,但是既不具备完美的一致性,也不具备完美的可用性
BASE和ACID不是非非此即彼的关系
两者之间存在着多个逐渐过渡的权衡方案
放宽持久性
放宽持久性可以换取更好的性能
大大提高请求响应的时间
复制持久性
确保主节点收到某些副本对更新数据的确认之后,再告知用户它已经接纳此更新
仲裁
一致性和持久性之间的问题
不是非此即彼的问题
处理请求所用的节点越多,避免不一致问题的能力就越强
但是延迟也就越高
写入仲裁
就是Paxos中的超过半数投票才能通过该议案
读取仲裁
想要保证能够读取到最新的数据
必须要多少个节点联系才行
假设一个写入操作沟通了K个节点
那么想要读取到最新的数据,至少要和K+1个节点沟通
版本戳
事务分为商业事务和系统事务
商业事务
类似于锁库存,开始填写订单信息
系统事务
填写完订单信息,提交表单
商业事务的问题就是在需要计算和决策的时候
数据有可能已经发生了改动
这种问题可以采用离线并发的技术
乐观离线锁,也就是条件更新
也就是版本戳
比如http中的Etag
创建版本戳的方法
- 计数器,每次+1
- GUID,GUID是微软对UUID这个标准的实现
- 根据资源内容生成Hash
- 使用上次更新的时间戳 不需要主节点来生成 但是所有节点的时钟必须同步 同时精度要高
主从复制,更新不一致的情况
节点每次复制的时候,带上版本戳
这样从从节点中读的话,版本低的那个就说明数据较旧
万一是对等式NoSQL系统
最常用的版本戳形式 叫 数组式版本戳
就是每个进程都维护一个进程版本戳的数组
[server1:12, server2:32, server3:64]
这是三台主服务器的情况
如果两个版本戳中都有一个比对方大,那么就是发生了写入冲突
但是无法解决这个问题
MapReduce
Hadoop
在集群上运行,执行并发操作
Map从聚合中读取数据,缩减为相关的键值对
Map会产生很多具备同一关键词的值,而化简任务将他们简化为单一的输出值
流式处理
增量式的MapReduce
KV
适用场景
- 会话信息
- 用户配置信息
- 购物车
不适用场景
- 数据间关系
- 含有多项操作的事务
- 查询value
文档数据库
感觉格式就是JSON啊
也支持主从复制
副本集通过内部选举得到主节点,但是可以人工干预
和KV不同的是
文档数据库可以查询文档中的数据
可扩展性
就是弹性伸缩
动态加机器,减机器
和Redis差不多啊
列族数据库
Cassandra能快速执行跨集群写入操作并易于对此扩展的数据库
集群中没有主节点,每个节点均可以处理读取和写入请求
每个列族都可以与关系型数据库的“行容器”相对照
两者都用关键字标识行
并且每一行都由多个列组成
区别在于列族数据库的各行不一定要具备完全相同的列
还拥有超列族
Cassandra没有传统意义上的事务
写入操作在行级别是原子的
Cassandra的可用性极佳
当W + R > N的时候
一致性极佳
Cassandra和Redis的对比
看的网上的,自己简单总结下
- Redis的数据总体还是面向聚合的,适用于快速,数据量小的情况
- Cassandra所支持的数据量可以非常大,同时在灵活性上确实比Redis高一点
图数据库
有大量互相关联的节点
用节点和边建立好图之后,可用多种方式查询它
查询图也叫遍历
图数据库的一个好处就是,无需改变节点和边,即可应对新的遍历需求
一般不支持集群部署
Neo4J是兼容ACID事务的数据库
可用性
主从复制
分片困难
因为不是面向聚合的
适用场景
社交网络关系
